The Power of LoRA in Modern MLOps

As the AI community continues to push the boundaries of what's possible with large language models (LLMs), a new paradigm is emerging—one that values specialization and efficiency over sheer scale. Enter Low-Rank Adaptation (LoRA), a method that is redefining how we approach model fine-tuning and deployment in MLOps.
What Is LoRA?
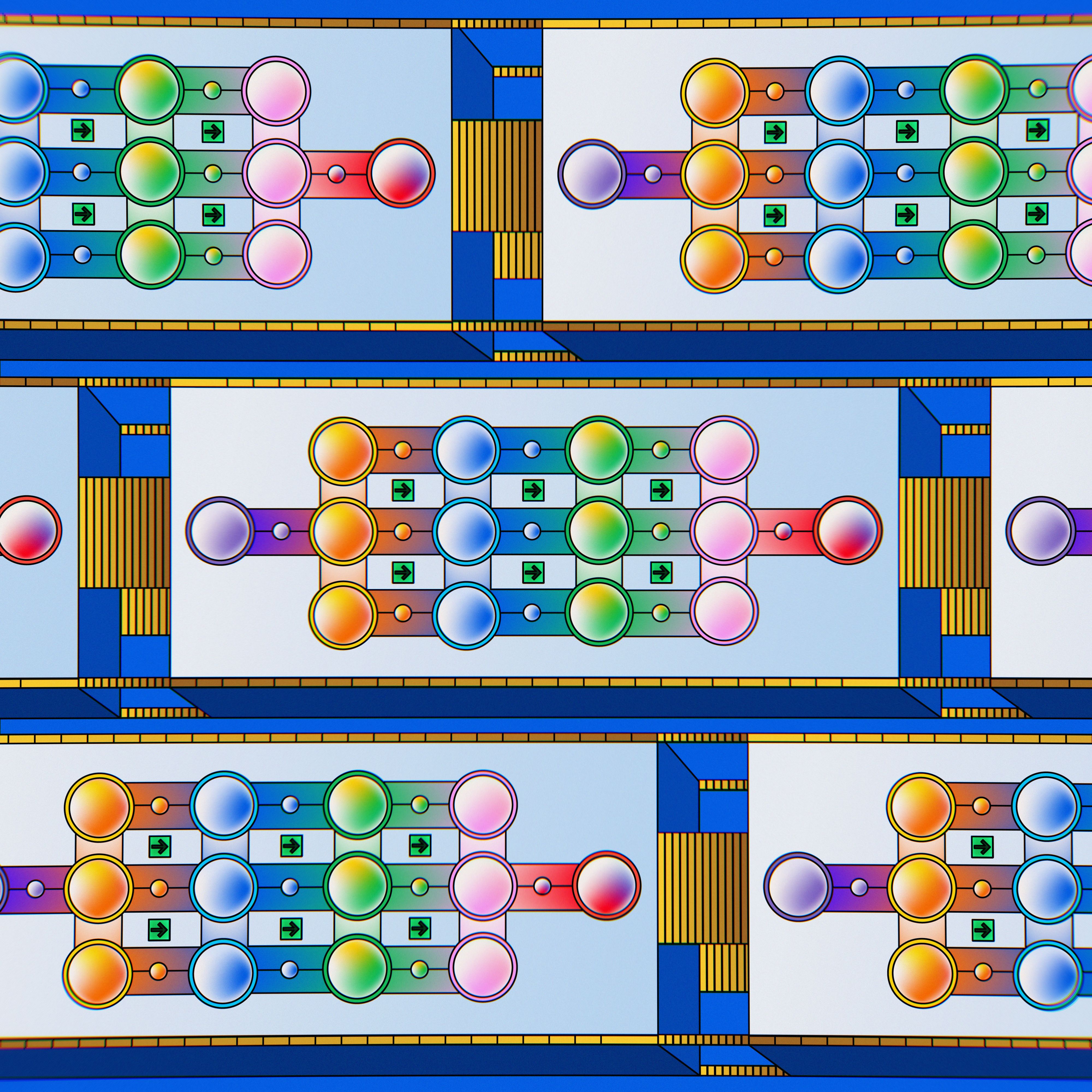
LoRA stands for Low-Rank Adaptation, a method introduced to fine-tune large neural networks more efficiently. Instead of updating all the parameters of a pre-trained model, LoRA inserts low-rank trainable matrices into each layer of the transformer architecture. This approach significantly reduces the number of parameters that need to be updated during fine-tuning, making it both computationally efficient and storage-friendly.
The Shift Towards Specialized Models
In the race to develop state-of-the-art models, the industry has often equated bigger with better. However, this isn't always the case, especially for enterprise applications that require:
- Reliable targeted data extraction (avoiding hallucinations in extraction)
- Minimal hallucinations
- Strict data isolation between clients
Large, general-purpose models like GPT-4 or Claude 3.5 are powerful but can be an overkill for specific tasks that demand precision and reliability. Smaller, specialized models fine-tuned for particular tasks can offer better performance in these scenarios.
On-the-Fly Adaptation with LoRA
One of the most compelling features of LoRA is its ability to enable on-the-fly adaptation of base models using client-specific weights. Here's how it works:

1. Load Base Weights: A pre-trained base model is loaded into memory. This model serves as the foundation for all tasks.
2. Apply LoRA Weights: Depending on the client's request, specific LoRA weights are applied to the base model. These weights are small, task-specific adaptations that tailor the model's behavior.
3. Run Inference: The adapted model is then used to perform the desired task, ensuring that the output is customized to the client's needs.
This dynamic adaptation allows for a high degree of flexibility without the overhead of loading multiple large models into memory.
Efficient Inference on CPU Clusters
Running large models typically requires GPU clusters, which can be expensive and energy-intensive. However, by using LoRA in conjunction with model quantization techniques, it's possible to run inference efficiently on CPU clusters. Quantization (adjusting the precision of calculation to reduce model size in inference) reduces the precision of the model's weights, which decreases computational requirements without significantly impacting performance—especially when fine-tuned for specific tasks.
Benefits for Enterprise Applications at SageX

At SageX, we prioritize enterprise requirements that demand:
- Data Privacy: Ensuring that data from one client doesn't contaminate models used by another.
- Reliability: Providing consistent and accurate outputs.
- Efficiency: Optimizing resource usage to reduce costs.
By leveraging LoRA, we can maintain a single base model and adapt it for multiple clients securely. Each client's data is used to generate their specific LoRA weights, which are isolated and do not affect the base model or other clients' adaptations.
Avoiding Hallucinations and Ensuring Accuracy
Hallucinations—when a model generates inaccurate or nonsensical information—are a significant concern in enterprise applications. Specialized models fine-tuned with LoRA are less prone to hallucinations because they're trained on task-specific data, reducing the model's uncertainty during inference.
Implementing LoRA in MLOps Pipelines
Integrating LoRA into existing MLOps pipelines involves several key steps:
1. Data Collection: Gather client-specific data relevant to the task.
2. Fine-Tuning with LoRA: Use the data to train the low-rank adaptation matrices while keeping the base model weights frozen.
3. Version Control: Store LoRA weights separately, enabling easy updates and rollbacks without affecting the base model.
4. Deployment: Implement a system where the base model is loaded once, and LoRA weights are applied as needed per request.
5. Monitoring: Continuously monitor performance to ensure the adapted models meet the required standards.
The Future is Specialized and Efficient

The trend towards ever-larger models is not sustainable for all applications. By focusing on specialization and efficiency, we can build models that are not only effective but also practical for real-world use cases. LoRA represents a significant step in this direction, offering a scalable and adaptable solution that aligns with enterprise needs. At SageX, we're excited to continue leveraging this technology to provide our clients with reliable, efficient, and secure AI solutions.
Conclusion
The landscape of language models is evolving. While large, general-purpose models have their place, the future lies in specialized models that can be efficiently adapted to specific tasks and clients. LoRA offers a sophisticated yet practical approach to achieving this, enabling on-the-fly adaptation, efficient CPU-based inference, and adherence to stringent enterprise requirements. By embracing techniques like LoRA, we move towards a more sustainable and effective paradigm in AI—one where models are not just larger, but smarter and more aligned with the needs of those who rely on them.
Related Posts


Interested in Simplifying Your Data Extraction?
